XML Structural Summaries and Microformats October 31, 2007
Posted by shahan in eclipse plugin, information retrieval, search engines, software architecture, software development, visualization, XML.add a comment
From my experiences attempting to integrate microformats into XML structural summaries, the results have all been workarounds.
Microformats are integrated into an XHTML page through the ‘class’ attribute of an element. I won’t go into the issues with doing this and while the additional information embedded into the page is welcome, it doesn’t conform to the standardized integration model offered by XML. A good reference on integrating and pulling microformat information from a page is here.
Microformats are not easily retrieved from a page because there is no way to know ahead of time what formats are integrated into the page. A workaround in creating an XML structural summary based on microformats can be obtained by applying an extension of the XML element model to indexing attributes and furthermore their values (in order to identify differing attributes). Since the structural summaries being developed using AxPREs are based on XPath expressions, they will be able to handle microformats but with advanced planning on the user.
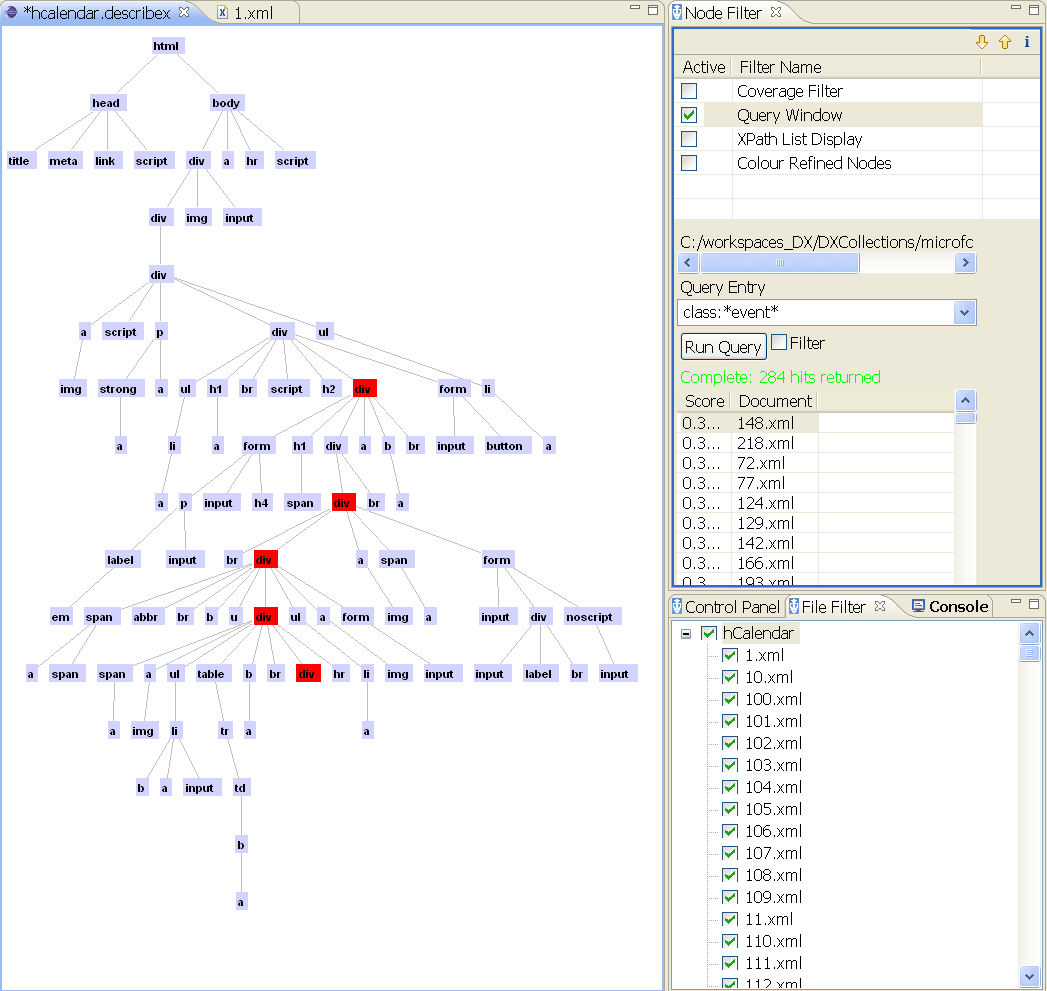
The screenshot below is of DescribeX with a P* summary of a collection of hCalendar files. Using Apache Lucene, the files are indexed to include regular text token, XML elements, XML attributes and their associatd values. On the right-hand side you can see a query has been entered searching using Lucene’s default regex ‘*event*’ to search for ‘class’ attributes that contain that term. The vertices in red represent the elements which contain it and while it would be nice to assume that the descendants of the highlighted vertices are related to hCalendar events, it is not the case.
Published: Exploring PSI-MI XML Collections Using DescribeX October 2, 2007
Posted by shahan in publication, software development, standards, visualization, XML.Tags: publication, standards, XML
1 comment so far
My first official publication 🙂 Thanks to Reza for putting so much hard work into it as well as his patience for some of the DescribeX bug fixes. Many thanks also go to my professors Mariano and Thodoros who guide and encourage at every opportunity.
Abstract
PSI-MI has been endorsed by the protein informatics community as a standard XML data exchange format for protein-protein interaction datasets. While many public databases support the standard, there is a degree of heterogeneity in the way the proposed XML schema is interpreted and instantiated by different data providers. Analysis of schema instantiation in large collections of XML data is a challenging task that is unsupported by existing tools. In this study we use DescribeX, a novel visualization technique of (semi-)structured XML formats, to quantitatively and qualitatively analyze PSI-MI XML collections at the instance level with the goal of gaining insights about schema usage and to study specific questions such as: adequacy of controlled vocabularies, detection of common instance patterns, and evolution of different data collections. Our analysis shows DescribeX enhances understanding the instance-level structure of PSI-MI data sources and is a useful tool for standards designers, software developers, and PSI-MI data providers.
Reference
Reza Samavi, Mariano Consens, Shahan Khatchadourian, Thodoros Topaloglou. Exploring PSI-MI XML Collections Using DescribeX. Journal of Integrative Bioinformatics, 4(3):70, 2007. Online Journal: link
TReX and XSummary November 5, 2006
Posted by shahan in information retrieval, software development, XML.add a comment
Currently, as part of my Research Assistanceship supervised by Dr. Consens, I have worked with several of the existing code bases. One is called TReX which was used in the Initiative for the Evaluation of XML Retrieval (INEX). INEX is a global effort consisting of over 50 groups who participate by working on a common XML document collection (Wikipedia this year, IEEE articles last year). The sharing of results promotes an open research environment and also helps direct future research initiatives. I am in the process of refactoring and separating the implementation of TReX into discrete and modular components. The refactoring process is challenging but very rewarding as it requires understanding not only how tightly integrated the data structures are with each other, but also what the code is actually doing and why. One tool I found very helpful in understanding the system as a whole is an Eclipse plug-in called Creole. It provides the ability to visualize the java packages, classes, method calls, and even view the source code all from within a common interface with boxes and arrows. The most useful feaure applied against TReX was the ability to view the building of the code through the CVS check-ins. Further, a cross-listed course (one which is both an undergraduate and graduate level) I took this summer of 06, Software Architecture and Design taught by Greg Wilson, was extremely useful as it taught how software patterns can help prevent the problems facing the code currently. Greg taught ways of thinking about the structure of software in order to allow for effective expansion. The paper Growing a Language by Guy L. Steele Jr. is an excellent read which describes the concept of growth, while not directed towards software design, the concepts and notions are equally applicable. It is also a very easy read which may at first glance seem very strange.
A second code base which I have worked with is called XSummary, which summarizes the structure of XML document collections. It was demonstrated at the Technology Showcase at IBM’s CASCON 2006 in mid-October. It is an Eclipse plug-in developed using the Zest visualization toolkit. It presented structural summaries of various XML document collection applicable to Wikipedia, BPEL, blog feeds in RSS and Atom. It depicts the parent-child relationships of XML structural elements and allows addition of detail through displaying of different summaries on a particlular element. XSummary is developed by Flavio Rizzolo. I also integrated a coverage and reachability model developed by Sadek Ali. Coverage and reachability provide a way of identifying which elements are considered important within the colleciton with the ability to specify a range, thus simplying the detail level by displaying only the elements within a slider-selected range.
Python for Software Carpentry October 9, 2006
Posted by shahan in software development.add a comment
The advantages of Python as an easy-to-learn scripting language fit very well into the niche of supporting the quick and efficient development of software. The language is well defined, provides extensive library support, and is multi-platform. The ability to leverage short but powerful scripts enables productivity, allowing focus to be maintained on the real project at hand. In only one evening, I was able to apply: command line parameters, functional programming, system calls, input/output handling, and lists as values within dictionaries. Future work will involve the addition of graph outputs and automated builds.
The clear and concise open source Software Carpentry course addresses concerns geared towards scientists but is also applicable to more familiar developers as well.
