XML Structural Summaries and Microformats October 31, 2007
Posted by shahan in eclipse plugin, information retrieval, search engines, software architecture, software development, visualization, XML.add a comment
From my experiences attempting to integrate microformats into XML structural summaries, the results have all been workarounds.
Microformats are integrated into an XHTML page through the ‘class’ attribute of an element. I won’t go into the issues with doing this and while the additional information embedded into the page is welcome, it doesn’t conform to the standardized integration model offered by XML. A good reference on integrating and pulling microformat information from a page is here.
Microformats are not easily retrieved from a page because there is no way to know ahead of time what formats are integrated into the page. A workaround in creating an XML structural summary based on microformats can be obtained by applying an extension of the XML element model to indexing attributes and furthermore their values (in order to identify differing attributes). Since the structural summaries being developed using AxPREs are based on XPath expressions, they will be able to handle microformats but with advanced planning on the user.
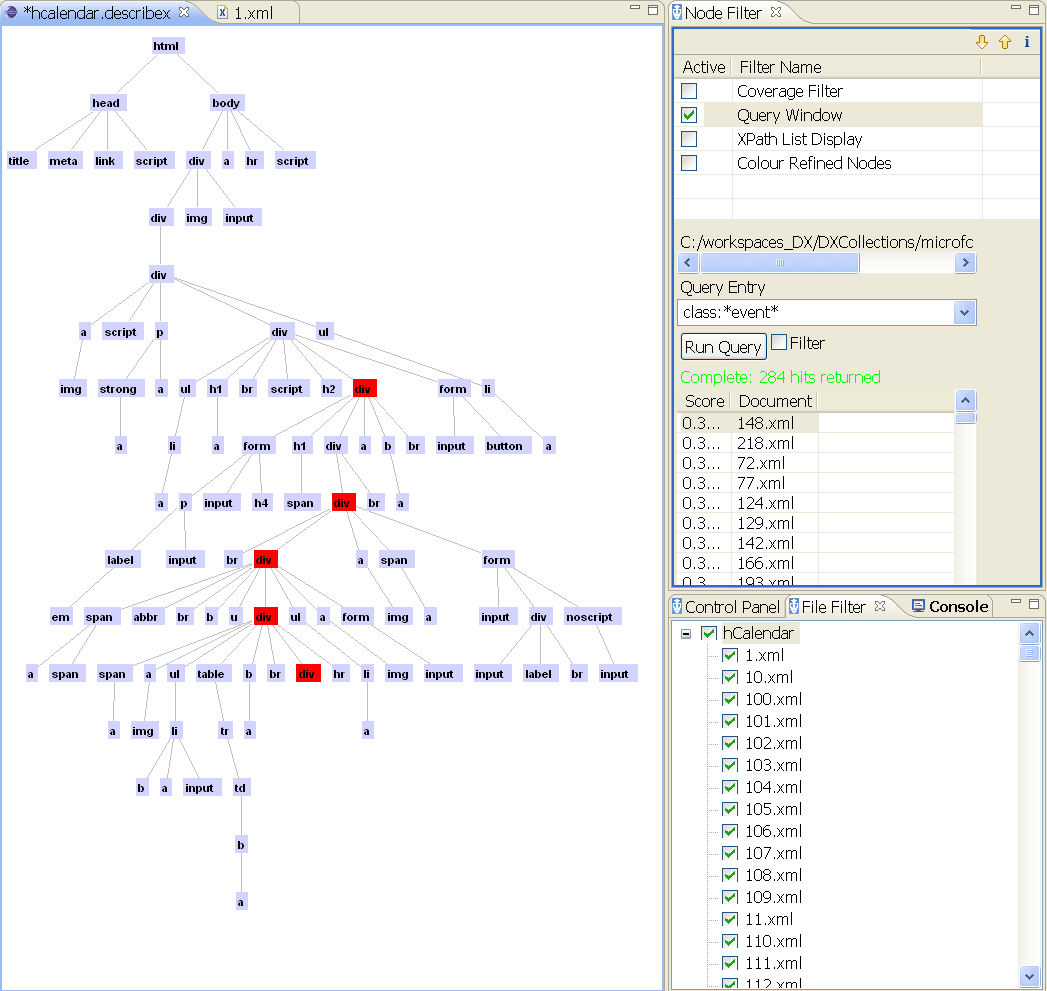
The screenshot below is of DescribeX with a P* summary of a collection of hCalendar files. Using Apache Lucene, the files are indexed to include regular text token, XML elements, XML attributes and their associatd values. On the right-hand side you can see a query has been entered searching using Lucene’s default regex ‘*event*’ to search for ‘class’ attributes that contain that term. The vertices in red represent the elements which contain it and while it would be nice to assume that the descendants of the highlighted vertices are related to hCalendar events, it is not the case.
Design Pattern: Chain of Command or Chain of Responsibility September 21, 2006
Posted by shahan in software architecture.add a comment
When programming, certain sections of code can sometimes be viewed as a workflow or preset sequence of tasks or commands. This can considered to be the design pattern called Chain of Command or alternatively, Chain of Responsibility. What this implies is that there is a container, the Context, which contains the objects processed by the workflow, which can be added and removed, by each Command in the Chain.
There are various models to define and implement these workflows, the easiest being writing the code as is (which isn’t much of a model). This introduces a level of formality in the workflow, any changes require source code changes and recompilation.
One alternative is to use a Java dynamic class loader (which contains the workflow) after some decision making process. With some small amount of creativity, this technique allows for new workflows to be created without having to modify and recompile the original source code, only the workflows. This may introduce undesirable runtime errors.
Another viable alternative is to use the Apache Chain library. The performance is very reasonable, the implementation, and configuration through XML files make it a treat to use. For performance, an empty Command (configured through the XML configuration file) was called for each word encountered in a set of 750 files through the use of a tokenizer, resulting in only an approximate 500ms processing delay (not counting startup costs or memory footprints, further results may follow).
